
こんにちは。SREチームの川野です。
アプリケーションログを可視化するにあたって考えたことなどをまとめてみたのでその紹介をしていきたいと思います。
※この記事はGRIPHONE Advent Calendar 2018 17日目の記事です。
https://adventar.org/calendars/3147
https://qiita.com/advent-calendar/2018/griphone
この記事で伝えたい事
ミドルウェアの扱い方の云々というのはブログ等で散見されると思うのですが、今回は「なぜその選択をとったか」ということの理由とか考えた流れをお伝えできればいいかなと思っています。
経緯
GRIPHONEで運用しているアイドルうぉーずでは以下のアーキテクチャー(一部)をとっています。
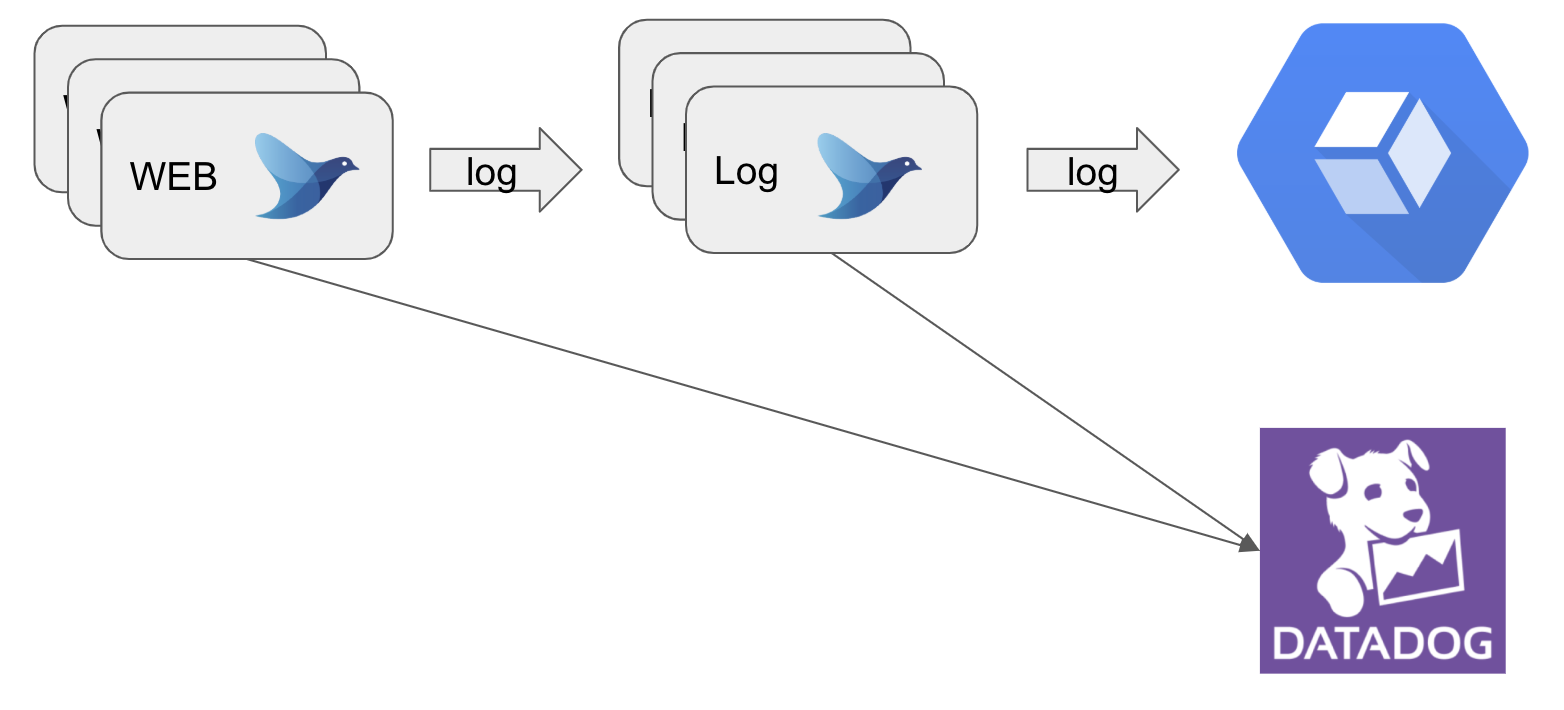
現状ではアプリケーションのログは上記の構成のようにWEBサーバからログサーバを経由し、GCPのStackdriverLoggingに転送しています。StackdriverLoggingでログをフィルタリングして検索は簡単にできます。しかし、障害発生後に調査していてはなかなかボトルネックを見つけ出すことができません。そこで、ログを可視化し毎日チェックすることで異常を早く見つけられるのではないかと考えました。また、アプリケーションエンジニアがみても直ぐに現状の問題点に気づくことができるダッシュボードを作ることをOKR目標に掲げており、それに取り組んでいます。アプリケーションエンジニアが日常的にダッシュボードを見てくれるようになれば、メトリクスが大きく変わった時に行ったリリースのコードに問題がないか?など直ぐに当たりを付けて調査することが可能になります。
アプリケーションログを表示するために以下の2つの要素を考え、経費コストや実現方法、運用上に関して問題ないかなどを踏まえて選定していきました。
1. 何のツールを使ってモニタリングするか
2. その選んだツールとの連携
大雑把ですが考えられた候補は以下のものになります。
1.モニタリング候補
StackdriverMonitoring
・StackdriverLoggingを使っているので一番連携が簡単
・有料
・[料金 | Stackdriver ドキュメント | Google Cloud ]
調べたところ現状StackdriverLoggingに掛かっている費用の約12倍でした・・・
DatadogLogs
・DatadogLogsに送信したログからpipelineなどを使って色々なグラフを作成できる
・ダッシュボードのグラフから直接ログを参照できる
・有料
・pipelineの設定はDatadogの画面からポチポチと操作をして行うのでコード化できない。
・GCPのインテグレーションのサポートがもう直ぐなので気長に待ちたい(願望)
・[Log Explorer]
・[DataDog Log Managementを使って、インフラダッシュボードから関連するログまでひとっ飛び – Qiita ]
・[Datadog Logs(パブリックベータ) ログ収集設定 | cloudpack.media ]
ログモニタリングはStackdriverLoggingに一貫させたく、アプリケーションログを可視化させるにはグラフから直接ログへ遷移できて便利ですが、アプリケーションログを可視化するという要件に対しては過剰であると判断しました。そしてコストもかかります。
DogstatsD
StatsDをDatadogインテグレートしたもので、メトリクスを送信する方法として以下の5つが用意されています。[DogStatsD を使った、メトリクスの送信 ]
・カウンタ(Counters)
・ゲージ(Gauges)
・ヒストグラム(Histograms)
・セット(Sets)
・タグ(Tags)
このヒストグラムを使えばパーセンタイルやカウント、最大値といったメトリクスを同時に生成してくれるので、これが使えそうだな!となりました。また、dd-agentのコンフィグにて以下のように書くことで欲しいパーセンタイルを追加することもできます。
(デフォルトだと、50パーセンタイルと95パーセンタイルのみ)
histogram_percentiles: 0.95, 0.75
dd-agentが動いているサーバ上で試しに以下のコマンドを実行してみると簡単にメトリクスが作成されるのがわかります!
$ echo 'hello.world:2|g' > /dev/udp/localhost/8125
DogstatsDと似たようなものにAgentCheckというのもあるのですが、既存インテグレーションに対してカスタムしたい時に使うものだと認識しています。最初はDogstatsDとAgentCheckが混在して必死にAgentCheckを使って実装を行っていました・・・
2.ログ送信方法
Norikra + fluentdプラグイン
新しいミドルウェアを追加するということは導入者が第一に詳しくなる必要があるのと、現状のアーキテクチャーから更にミドルウェアを増やすと複雑化してしまうという懸念があります。また、Norikraは恐らく分散処理が可能で各サーバーに配置させることになるのですが、どれくらいの負荷がかかるのかなど予測が立てられないので導入は難しいと判断しました。厳密には、そのミドルウェアを詳しく調べていくのと負荷テストに掛ける工数がそれほどないという視点からの判断です。
Pub/Sub + CloudFunction
GCP->SQLログ->BigQuery
GCP->アプリケーションログ->Pub/Sub
GCP->その他->GCS
とできるのでアーキテクチャ的にはスッキリしていいなと思ったのですが、処理するログを減らしても10TB/月ほどになるので、Pubsubの料金は毎月約7万になります。それに加えて、DatadogLogsの料金とCloudFunctionの料金が掛かるでそこそこ費用かかるなあといった具合です。
最終的には、fluentdでなるべくプラグインを使わないようにして、実装していくことにしました。後でまた増えるかもしれませんが、以下のプラグインのみで事足りました。
・fluent-plugin-dogstatsd
結果的に
元々監視ツールとしてDatadogを使用していたので、Datadogに寄せたい&コストかからずシンプルに要件を満たせるものがDogstatsDでした。
fluentd 0.12系を使っているので、実装中、バージョン差異でプラグインが使えないものなどが出て来たりして大変でしたが、結果的にあまりプラグイン使う必要はなくなりました。
今後の方針
・fluent-plugin-gcloud-pubsub-customを使ってGCPのLBのログなどもfluentdに流す
・fluentBitを使ってWEBサーバを軽量化
などを考えています。集計処理などはまだ出来ていませんが、latencyの大きいURIを表示したりするのはログを送信する際にtagなどに対してURIパラメータを設定すれば何とか表示はできそうな感じです。必要であれば別のfluentdプラグインを使っていこうと思います。