
こんにちは!SREの川野です。
今回は、MHAを運用していて起こった障害と簡単にできる対策をまとめてみました。
MHAについて
まずはじめに簡単ですがMHAについて説明しようと思います。
MHAとは
MySQL Masterの冗長化を行うためのソフトウェアです。Perlで作られています。
GitHub : https://github.com/yoshinorim/mha4mysql-manager
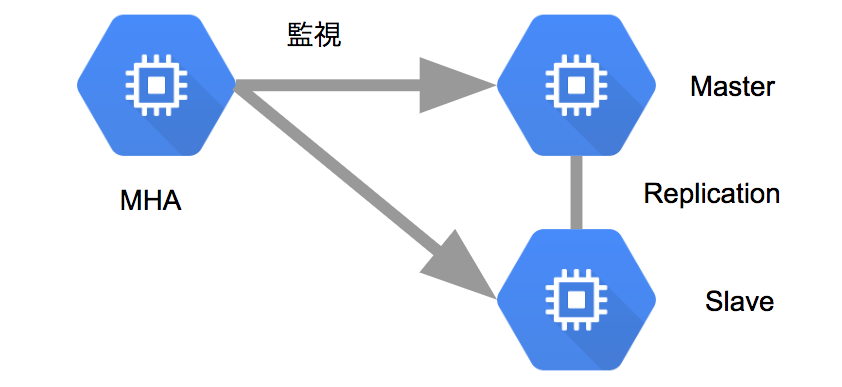
主に以下の2つの役割を持っています。
- MySQL DBクラスタを監視する
- Masterに障害を検出した場合、FailOverさせる
アーキテクチャー
コンポーネント
- MHAマネージャ
MySQL DBクラスタの監視、FailOverの制御などの役割を持っています。
- MHAノード
MySQLバイナリ/リレーログの解析、リレーログを他のSlaveに適用するリレーログの位置の特定、ターゲットSlaveへのイベントの適用などの役割を持っています。
監視について
はじめにMHAは設定ファイルに書かれているDBクラスタの各ホストに接続します。そしてレプリケーション設定を確認し、現在のMasterの識別を行います。
その後は、Masterのみを監視し続けます。Slaveの停止・再起動・追加・削除は、MHAの監視には影響しません。
障害検知について
Masterに対して SELECT 1 というクエリを実行してMasterが正常かどうかを判断しています。3回連続してクエリの実行に失敗した場合は障害として検知し、FailOver処理へ進みます。
FailOverについて
障害検知後にFailOver処理を行うのですが、
Masterサーバに対してSSH接続ができるかできないかによって処理内容が以下のように異なります。
- SSHができる場合 : サーバ内のmysqld, mysqld_safeプロセスを全てSIGKILLした上でSlaveを新Masterとして昇格させます
- SSHができない場合:Slaveを新Masterとして昇格させます(一般的には、power_managerスクリプトを利用してMasterサーバを停止処理させるケースが多いかと思います)
MHAについて、ざっくりとした説明は以上になります。
起こった事象
ある日、Masterサーバでネットワーク障害が起き、以下のような事象が起こりました。
1. mysqldプロセスが落ちていないのにプロセスの死活監視アラートが飛んだ(Datadogを使用)
2. ネットワーク障害が起きているMasterをMHAが障害検知できずにFailOverさせることができなかった
3. サービスやレプリケーションには影響がなかった
4. SSH接続やその他ミドルウェア(consul, dd-agent)の処理でエラーが起きていた
考えたこと
以上のような事象が起こったのですが、
どうやら持続的なコネクションには影響が出ず、新規にコネクションを作成した場合にエラーを吐いていました。
- 事象1について
mysqldプロセスは生きていたのですが、Datadogで死活監視を行なっているmysqldプロセスチェックアラートは、ネットワーク障害によってサーバからメトリクス値を受け取ることができなかったと考えられます。 - 事象3について
サービスのアプリケーションはPHPで実装されており、pconnectで持続的なコネクションを使用していた為、影響がたまたま出ませんでした。仮にデプロイ等してphp-fpmが再起動してしまった場合は、新規にコネクションを作成しようとするのでコネクションエラーが出てサービスに影響が出ていたと考えられます。 - 事象4について
調査時にMasterに異常があると考え、SSHを試みてもタイムアウトになり接続できませんでした。こちらもまた新規コネクションを作成していたからであると考えられます。
サーバのTCPコネクション数(ファイルディスクリプタ数)の上限に引っかかっているのかもと考え調べましたが、そのようなことはありませんでした。
根本原因は掴めていないのですが、上記のことからもどうやら新規コネクションにおいてエラーを出していたという状況でした。
ここで重要なのは “事象2” の、MHAがこの事象に対してネットワーク障害を検知せずにFailOverしてくれなかったことです。
masterhaプロセスを起動したときに確立されたコネクションを使用して監視していた為に、MHAは今回のネットワーク障害について検知してくれることはありませんでした。
対策
バージョン0.53から、ping_type という監視をより厳密にできるパラメータが追加されています。
By default, MHA establishes a persistent connection to a master and checks master’s availability by executing “SELECT 1” (ping_type=SELECT). But in some cases, it is better to check by connecting/disconnecting every time, because it’s more strict and it can detect TCP connection level failure more quickly. Setting ping_type=CONNECT makes it possible. Starting from 0.56, ping_type=INSERT was added.
https://github.com/yoshinorim/mha4mysql-manager/wiki/Parameters#ping_type
masterha.cnf に ping_type=CONNECT を追加することでチェックのたびにTCP接続・切断を行います。デフォルトの
ping_type=SELECT はmasterhaプロセスを起動した時に確立されたコネクションを利用したチェックになってしまいます。
よって、ping_type=CONNECT を設定するだけで、今回のような事象が起こった時にMHAは障害検知をしてFailOverをしてくれるようになります。
masterha.cnf の設定例は以下になります。
[server default]
ssh_user=masterha
master_binlog_dir=/var/lib/mysql
remote_workdir=/var/lib/masterha
master_ip_failover_script=/usr/local/bin/master_ip_failover
ping_type=CONNECT # ここを追加検証方法
検証方法として、先ず検証用のDBクラスタとMHAマネージャの環境を本番同様の構成で準備します。そして、Masterサーバ上でMHAマネージャからのTCPパケットを破棄する以下のコマンドを実行することでFailOverされることを確認しました。
iptables -I INPUT -s [マネージャのIP] -p tcp -j DROP終わりに
上記の設定を加えたことにより、TCPコネクションレベルでの障害検知もできるようになりました。
デフォルトの設定値を変えるだけで、このような対応ができますので是非ご参考にしていただけると幸いです。